Predicting Heart Diseases using ML Algorithms
In this post I am going to use various classification algorithms like
- Logistic Regression,
- Linear SVM,
- rbf SVM,
- KNearestNeighbors,
- GaussianNB,
- DecisionTree,
- RandomForestClassifier,
- GradientBoostingClassifier. for more info about algorithms click here
to predict whether a person is likely or has higher probability or chances of getting heart diseases.
Dataset
This dataset contains 76 attributes, but all published experiments refer to using a subset of 14 of them. In particular, the Cleveland database is the only one that has been used by ML researchers to this date. The “goal” field refers to the presence of heart disease in the patient. It is integer valued from 0 (no presence) to 4.
For reference click here
Attribute Information:
1.age = age in years
2.sex= (1 = male; 0 = female)
3.cp = chest pain type
4.trestbpsr = esting blood pressure (in mm Hg on admission to the hospital)
5.chol = serum cholestoral in mg/dl
6.fbs = (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
7.restecg = resting electrocardiographic results
8.thalach = maximum heart rate achieved
9.exang = exercise induced angina (1 = yes; 0 = no)
10.oldpeak = ST depression induced by exercise relative to rest
11.slope = the slope of the peak exercise ST segment
12.ca = number of major vessels (0–3) colored by flourosopy
13.thal = 3 = normal; 6 = fixed defect; 7 = reversable defect
14.target = 1 or 0
Data Exploration
#importing libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings('ignore')df = pd.read_csv('heart.csv')df.head()

df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 303 entries, 0 to 302
Data columns (total 14 columns):
age 303 non-null int64
sex 303 non-null int64
cp 303 non-null int64
trestbps 303 non-null int64
chol 303 non-null int64
fbs 303 non-null int64
restecg 303 non-null int64
thalach 303 non-null int64
exang 303 non-null int64
oldpeak 303 non-null float64
slope 303 non-null int64
ca 303 non-null int64
thal 303 non-null int64
target 303 non-null int64
dtypes: float64(1), int64(13)
memory usage: 33.3 KB

plt.figure(figsize=(10,10))
sns.heatmap(df.corr(), annot=True)
plt.show()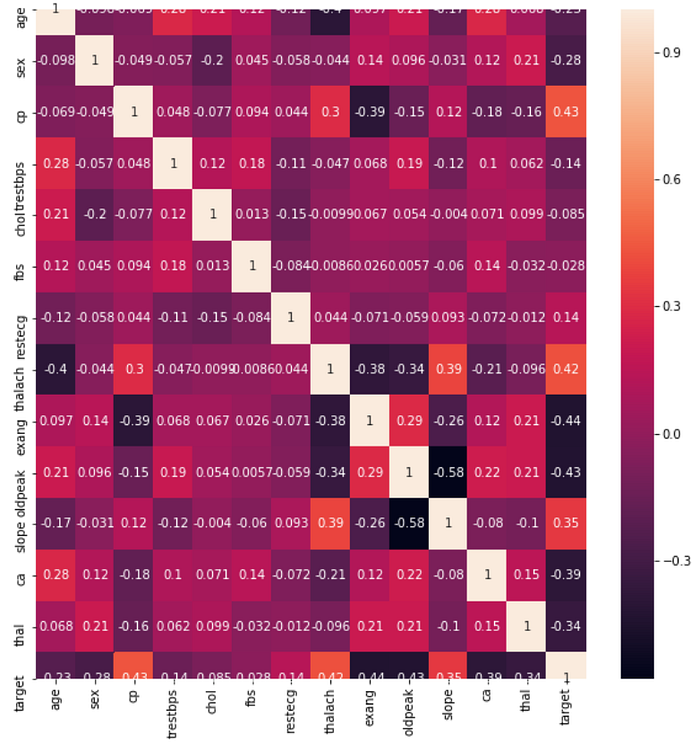
#age analysis
df.age.value_counts()[:10]58 19
57 17
54 16
59 14
52 13
51 12
62 11
44 11
60 11
56 11
Name: age, dtype: int64
Now using barplot to count values
sns.barplot(x= df.age.value_counts()[:10].index, y= df.age.value_counts()[:10].values )
plt.xlabel('Age')
plt.ylabel("Age counter")
plt.title("Age Analysis")
plt.show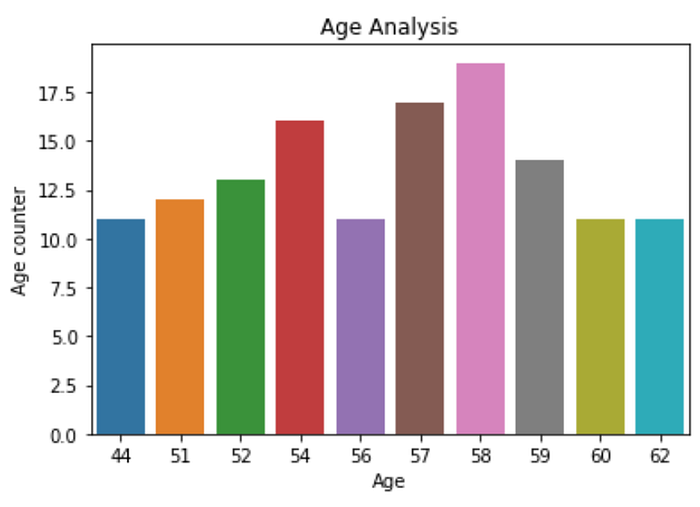
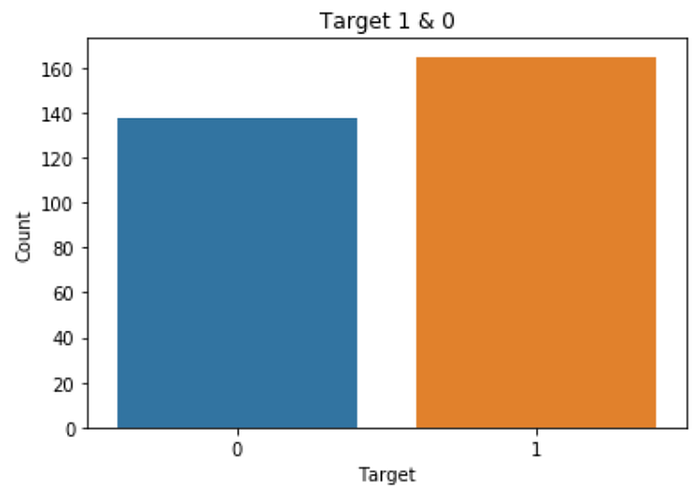
df.target.value_counts()
1 165
0 138we can see count of target of variables i.e., suporting cases for heart diseases.
countNoDisease = len(df[df.target == 0])
countHaveDisease = len(df[df.target == 1])
print("Percentage of patients that don't have heart disease : {:.2f}%".format((countNoDisease/(len(df.target)))*100))
print("Percentage of patients that have heart disease : {:.2f}%".format((countHaveDisease/(len(df.target)))*100))Percentage of patients that don't have heart disease : 45.54%
Percentage of patients that have heart disease : 54.46%countFemale= len(df[df.sex == 0])
countMale = len(df[df.sex == 1])
print(" Percentage of Female Patients : {:.2f}%".format((countFemale/(len(df.sex))*100)))
print("Percentage of Male Patients : {:.2f}%".format((countMale/(len(df.sex))*100)))Percentage of Female Patients : 31.68%
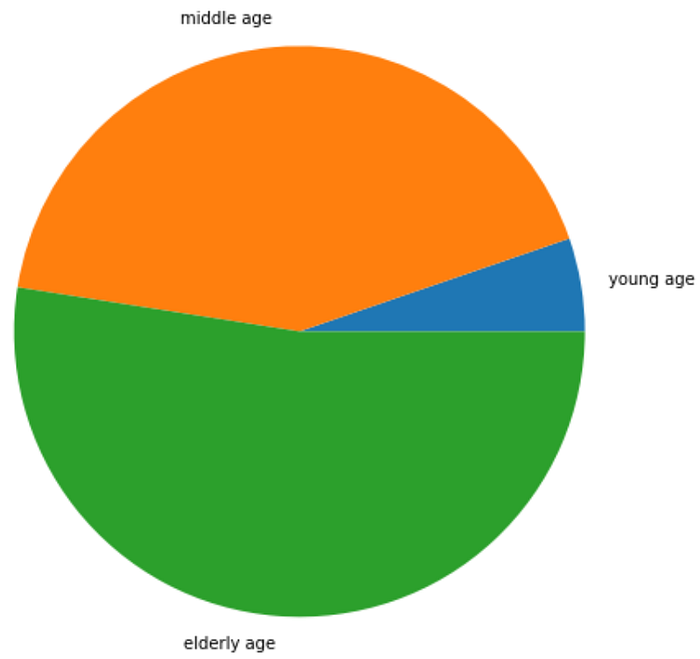
Percentage of Male Patients : 68.32%young_age = df[(df.age>=29)&(df.age<40)]
middle_age = df[(df.age>=40)&(df.age<55)]
elderly_age = df[(df.age>=55)]
print("Patients of Young age", len(young_age))
print("Patients of middle age", len(middle_age))
print("Patients of elderly age", len(elderly_age))Patients of Young age 16
Patients of middle age 128
Patients of elderly age 159colors = ['blue','green', 'cyan']
explode= [1,1,1]
plt.figure(figsize= (8,8))
plt.pie([len(young_age), len(middle_age), len(elderly_age)], labels=['young age', 'middle age', 'elderly age'])
plt.show()
#chest pain analysis
df.cp.value_counts()0 143
2 87
1 50
3 23
Name: cp, dtype: int64df.target.unique()
array([1, 0], dtype=int64)sns.countplot(df.target)
plt.xlabel('Target')
plt.ylabel('Count')
plt.title('Target 1 & 0')
plt.show()
Building the model
X_data = df.drop(['target'], axis = 1)
y = df.target.values
X_train, X_test, y_train, y_test = train_test_split(X_data, y, test_size = 0.2, random_state= 0)
# SHAPE OF TRAINING AND TESTING DATA
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)(242, 13)
(61, 13)
(242,)
(61,)from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC,SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier
# Importing functions to get the model fitting for the data
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,confusion_matrix
from sklearn.model_selection import cross_val_score
# Fitting all the models at the same time using 'for' loop
models=[LogisticRegression(multi_class="multinomial",solver="newton-cg"),
LinearSVC(),
SVC(kernel='rbf',gamma="auto"),
KNeighborsClassifier(n_neighbors=10,metric="euclidean"),
GaussianNB(),
DecisionTreeClassifier(criterion="gini",max_depth=10),
RandomForestClassifier(n_estimators=100),
GradientBoostingClassifier()
]
model_names=['LogisticRegression',
'LinearSVM',
'rbfSVM',
'KNearestNeighbors',
'GaussianNB',
'DecisionTree',
'RandomForestClassifier',
'GradientBoostingClassifier',
]
acc=[]
for model in range(len(models)):
classification_model=models[model]
classification_model.fit(X_train,y_train)
y_pred=classification_model.predict(X_test)
acc.append(accuracy_score(y_pred,y_test))
print("\n\n","confusion matrix of",model_names[model],"is ","\n",confusion_matrix(y_test,y_pred))
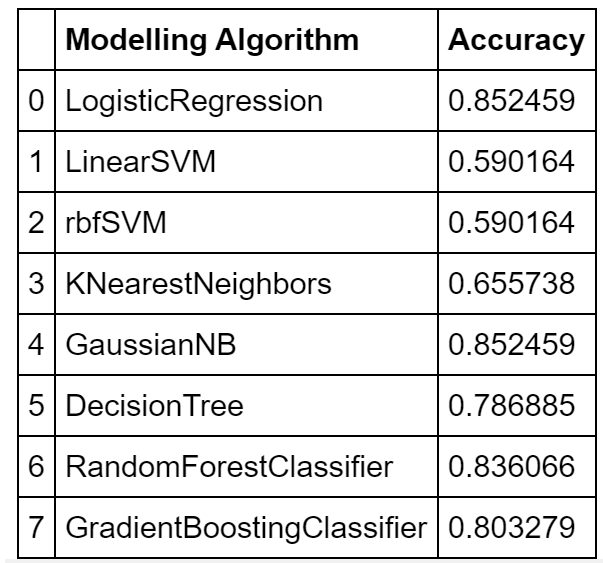
d={'Modelling Algorithm':model_names,'Accuracy':acc}
acc_table=pd.DataFrame(d)
acc_tableconfusion matrix of LogisticRegression is
[[21 6]
[ 3 31]]
confusion matrix of LinearSVM is
[[ 2 25]
[ 0 34]]
confusion matrix of rbfSVM is
[[ 2 25]
[ 0 34]]
confusion matrix of KNearestNeighbors is
[[19 8]
[13 21]]
confusion matrix of GaussianNB is
[[21 6]
[ 3 31]]
confusion matrix of DecisionTree is
[[22 5]
[ 8 26]]
confusion matrix of RandomForestClassifier is
[[21 6]
[ 4 30]]
confusion matrix of GradientBoostingClassifier is
[[21 6]
[ 6 28]]
sns.barplot(y='Modelling Algorithm',x='Accuracy',data=acc_table)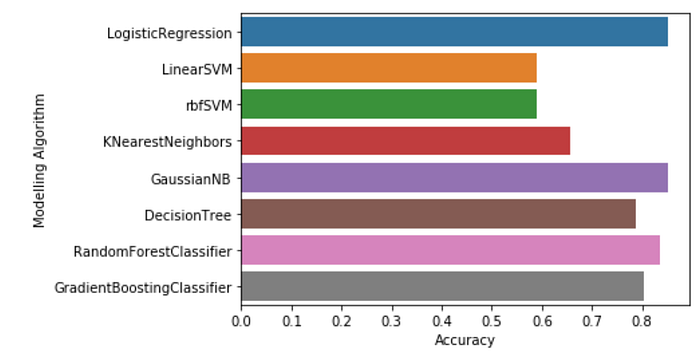
#Finding 10 fold cross validation scores for all the models at the same time using 'for' loop
models=[LogisticRegression(multi_class="multinomial",solver="newton-cg"),
LinearSVC(),
SVC(kernel='rbf',gamma="auto"),
KNeighborsClassifier(n_neighbors=10,metric="euclidean"),
GaussianNB(),
DecisionTreeClassifier(criterion="gini",max_depth=10),
RandomForestClassifier(n_estimators=100),
GradientBoostingClassifier()
]
model_names=['LogisticRegression',
'LinearSVM',
'rbfSVM',
'KNearestNeighbors',
'GaussianNB',
'DecisionTree',
'RandomForestClassifier',
'GradientBoostingClassifier',
]
cvs=[]
for model in range(len(models)):
classification_model=models[model]
clf=classification_model.fit(X_train,y_train)
scores = cross_val_score(clf, X_test, y_test, cv=10)
scores.mean()
print(model_names[model]," 10 fold cross validation score == ",scores.mean()," \n\n")LogisticRegression 10 fold cross validation score == 0.8280952380952382
LinearSVM 10 fold cross validation score == 0.6976190476190476
rbfSVM 10 fold cross validation score == 0.5585714285714285
KNearestNeighbors 10 fold cross validation score == 0.6742857142857142
GaussianNB 10 fold cross validation score == 0.7985714285714285
DecisionTree 10 fold cross validation score == 0.6776190476190476
RandomForestClassifier 10 fold cross validation score == 0.832857142857143
GradientBoostingClassifier 10 fold cross validation score == 0.7685714285714285
For Prediction we are taking values in the dataset itself and checking whether our model works

by giving this to the models we need to get “1” in our Predicted value.
new_obs=[[52,1,2,172,199,1,1,162,0,0.5,2,0,3]]
pv=[]
for model in range(len(models)):
classification_model=models[model]
models[model].predict(new_obs)
pv.append(models[model].predict(new_obs))
d={'Modelling Algorithm':model_names,'Predicted value':pv}
pred_table=pd.DataFrame(d)
pred_table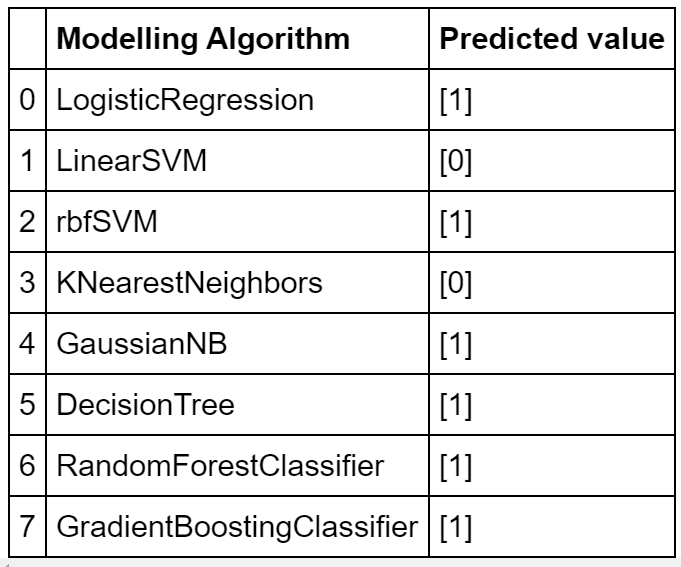
ALL MODEL PREDICTS PERFECTLY EXCEPT LINEAR & KNEAREST NEIGHBORS.
All outputs are bolded.
My Github Profile
References
- Analytics Vidya
- towards data science
- geeksforgeeks
- stackexchange
